Disclaimer: All opinions my own (not related to the company/team I work for). I know a tiny bit about data streaming systems and I only pretend to know LLMs.
Most data-intensive (long context or long generation) LLM tasks can be seen as a data processing operator that consumes one or two event streams that look like the following:
-- Continuous "query" defining the behavior of an LLM-based chatbot
CREATE CONTINUOUS VIEW response_stream AS
LLM_GENERATE(
PROMPT="Given conversation context and support docs, generate a helpful response.",
CONTEXT=STREAM(conversation_events), -- user interactions, updates incrementally
DATA_SOURCE=STREAM(support_docs_or_events) -- knowledge updates streamed incrementally
);
The conversation_events and support_docs_events here can either be seen as:
- Event streams (each event corresponds to a new entry that triggers incremental computation), or more broadly,
- Delta streams (each event corresponds to a modification—add/delete/update—that triggers incremental computation).
Depending on the application, the CONTEXT and DATA_SOURCE may be defined by different data streams:
- For an interactive chatbot,
CONTEXTwould be the current user prompt, andDATA_SOURCEwould be the conversation history of the session. - For summarization and data analysis apps,
CONTEXTwould be the summarization request (with customization), andDATA_SOURCEwould be the target docs/conversations/meeting notes/papers to summarize. - For a personal assistant,
CONTEXTwould be the spec used to capture user profile (e.g., basic information, calendar, work arrangements) and requests to complete work items (e.g., code review, slide generation).DATA_SOURCEwould be the memory (e.g., uploaded docs, code, meeting recordings, group chats), possibly summarized. - For a coding assistant,
CONTEXTwould be the code-generation/code-review/code-refactoring tasks, andDATA_SOURCEwould be the code file or project. - For RAG-QA,
CONTEXTwould be the question from the user, andDATA_SOURCEwould be the retrieved texts.
Updates to DATA_SOURCE
Updates to DATA_SOURCE should either be streamed to lower-level data storage first (e.g., knowledge base, vector DB, etc.) or pushed to LLM memory first (if users subscribe to the view).
Maintaining incremental states on vector DB
It seems most vector DBs do not natively support real-time view maintenance, and traditional streaming semantics are expensive to support in vector DBs—especially when graph-based indexing is used (i.e., update/delete/insert operations are expensive, and adding TTLs to each vector further increases maintenance overhead).
The most relevant work I’ve found discussing something similar to view maintenance in vector DBs is VectraFlow. VectraFlow maintains views incrementally for semantic-aware filter and top-K operations. The focus of the work, I think, is on reducing the number of views to check and update as new events occur (through clustering, which may involve accuracy/performance trade-offs).
Each individual view is maintained as a plain list (without a graph-based index), which might result in longer search/update times if the view contains a large amount of data.
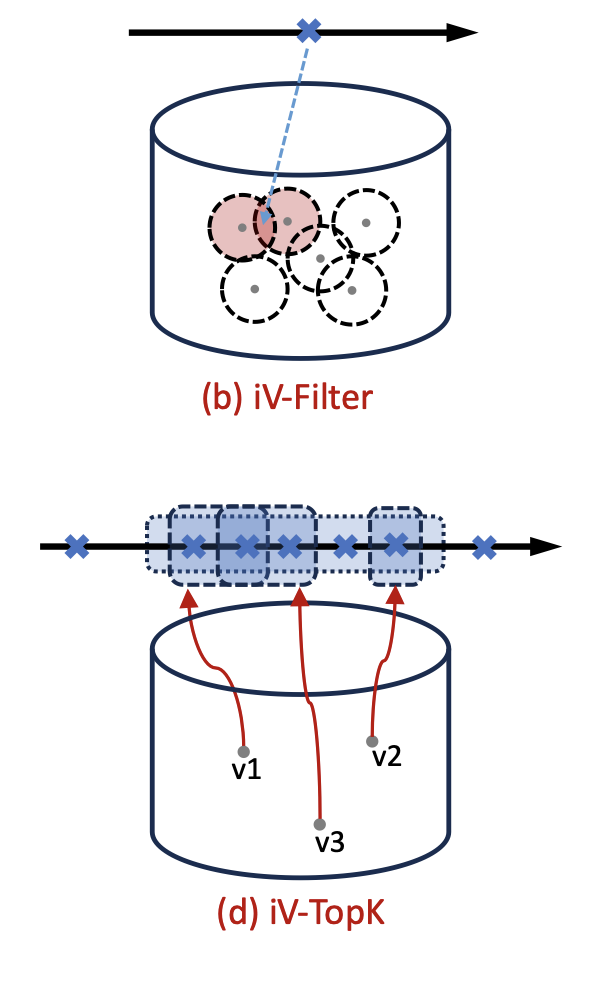
I think the authors might still be working on the full version of the work: it’d be interesting to see how this approach would affect result accuracy over time.
Maintaining incremental LLM memory (Textual Memory)
Using semantic operators: An example of imposing semantics on top of an LLM operator is LOTUS. One way to reason about LLM operation is to convert DATA_SOURCE into structured or unstructured data streams and convert CONTEXT into an operator with semantics.
This could convert a long-context QA example into the following: using Lotus as an example, the query 1. retrieves top papers most relevant to my research area, 2. generates insight for each paper, and 3. creates a digest summarizing the research insights.
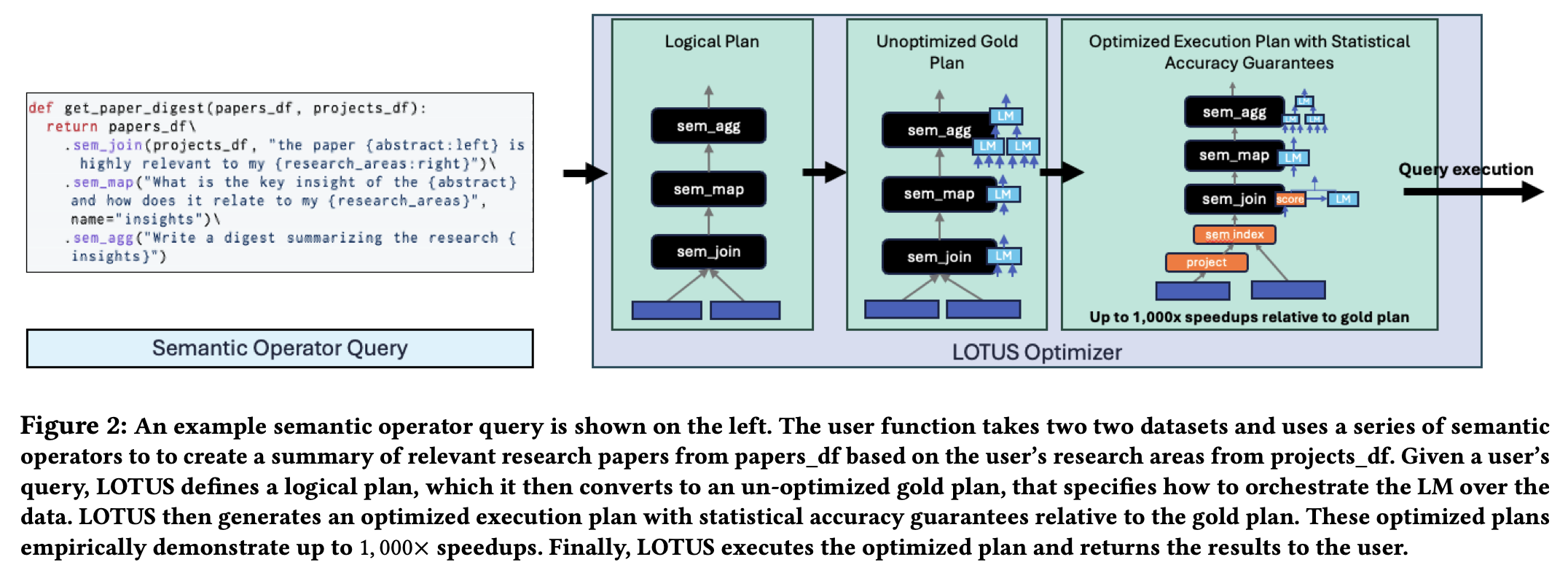
The semantic operators proposed are mostly similar to relational operators. Therefore, the idea of incremental view maintenance should transfer straightforwardly to this framework.
Say I make the following modification to my DATA_SOURCE (a collection of papers):
- Adding a new paper: If the paper is close to the target topic in vector space (via
sem_indexandsem_join), then the insight generated (viasem_map) would be pushed tosem_aggfor aggregation. The paper mentions one technique forsem_aggis incrementally folding new input, which naturally supports incremental computation. However, not all aggregation operations support incremental computation naturally, e.g., global ranking. - Removing a paper (or its expiration via TTL): If the removed paper wasn’t selected in the digest, this has no effect. Otherwise, we must:
- Maintain
sem_indexby removing the entry—this overlaps with Maintaining incremental states on vector DB. - Address the challenge of removing its contribution from
sem_agg, which is hard if the aggregation is not invertible (e.g., “Writing a digest summarizing research”). One optimization is to maintain partial computational results in memory for possible re-use, e.g., tree-based aggregation steps 1-2, 3-4, 1-2-3-4 takes three steps and modifying 4 to 4’ requires re-computation of 3-4’ and 1-2-3-4’, and we are able to re-use 1-2.
- Maintain
The figure above shows semantic operators in Lotus. Many of these are derived from relational operators, so modifications to DATA_SOURCE should map to existing literature.
Some operations like sem_filter and sem_map are easier to support incrementally—requiring one LLM inference each. Others like sem_join, sem_topk, and sem_agg require maintaining historical state or performing multiple inference requests. Whether sem_agg supports deletions depends on the language expression (e.g., natural language predicate) used by the user.
Additionally, the cost of using semantic operators could be high. Operators use LLMs to evaluate boolean predicates on input pairs (e.g., sem_join takes MxN LLM calls, sem_topk takes $O(NlogN)$). This is cheap and SIMD-friendly in databases but expensive in LLMs. This opens optimization avenues:
- Fine-tune small LLMs/adapters per operator
- Operator-specific quantization
- Leverage attention sparsity
- For instance, a query like
papers_df.sem_topk("the {abstract} makes the most outrageous claim", K=10)likely attends to names, numbers, or trigger phrases. Since each entry is reused frequently insem_topk, exploiting sparsity can yield efficiency without harming accuracy.
- For instance, a query like
Using UDF Operators: Semantic-aware LLM-based operators model DATA_SOURCE as bags of data tuples (like relational operators). But not all continuous LLM tasks could be expressed as semantic operators, especially when the operator is executed on unstructured data source (e.g., like a long document) or the task requires extracting complex reasoning steps that cannot be expressed as semantic operators. One common approach is first extract the structure and relationships of the data explicitly by LLM first, and then performs inference on extracted structured data one request is received (e.g., GraphRAG, HippoRAG).
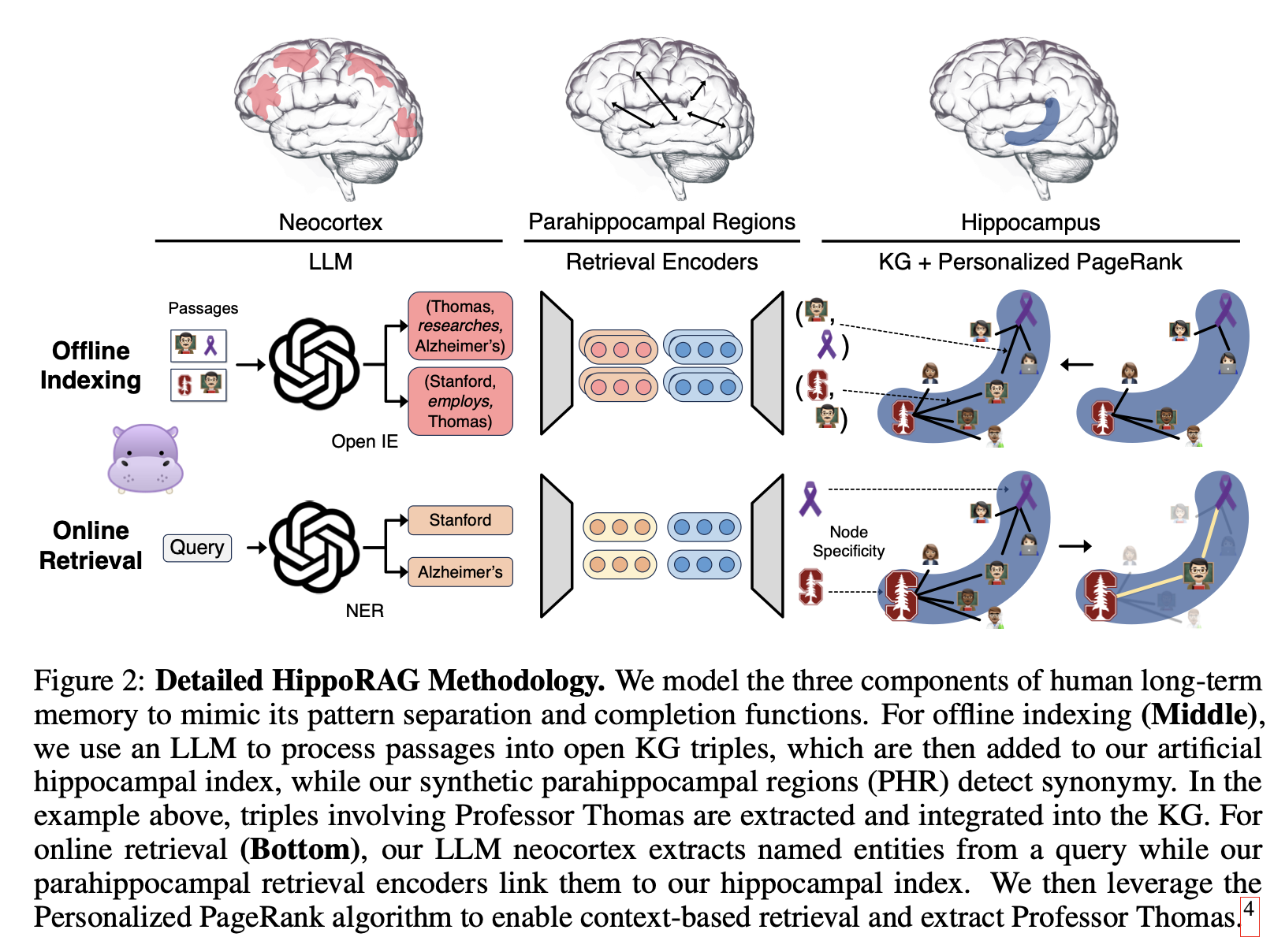
HippoRAG constructs a knowledge graph during an offline indexing phase to support reasoning in RAG QA. It claims to support incremental updates to the knowledge graph.
Compared to black-box UDF LLMs, these approaches explicitly convert DATA_SOURCE into structured graphs, simplifying the memory maintenance problem to a streaming graph update problem. Queries involve retrieving subgraphs and reasoning over them.
Thus, we can selectively update outputs when their input subgraphs change. Another insight from HippoRAG is that identifying key entities/relations is critical for accuracy.
HippoRAG makes reasoning explicit via a knowledge graph. However, reasoning is increasingly handled implicitly by LLMs, so the retrieval (or broader “information extraction”) is embedded in the inference process. This motivates studying how textual memory relates to parameterized memory.
Maintaining incremental LLM memory (Parameterized Memory)
Assuming the LLM can retrieve/reason from both context and its trained memory, can it “update” results when DATA_SOURCE changes?
2WikiMultiHopQA provides reasoning examples with annotated key entities and relations—almost like implicit graphs. The question: when the LLM reasons internally, can it incrementally maintain this reasoning if the dependency graph is implicit?

In general, we want LLMs to:
- Identify data source (parameterized memory, user-provided
DATA_SOURCE, or generated context). - Link output tokens to data sources.
- Track dependency structures over time.
- Use dependency structures to selectively update outputs when
DATA_SOURCEchanges—via:- Add (extend dependencies, regenerate as needed)
- Remove (invalidate/remove related outputs)
- Modify (track and recompute dependencies)
The goal is to keep the generated result up-to-date at low cost—especially when full recomputation is expensive or CONTEXT is frequently reused (e.g., summaries, notifications, function completion).
Three strategies to approach this:
- Append delta as conversation (expensive)
- Replace keywords (cheapest)
- Recompute sub-paragraphs (middle ground)
Append delta as part of conversation: For a model $LLM$, say we want to maintain a previously generated result $LLM(C)$ with initial context $C$. When the context is updated with $\Delta_{C}$, the most straightforward way to get an updated result is to call the model again with the new context and previously generated output as history:
$LLM(C + LLM(C) + \Delta_{C})$
As updates stream in, this forms a chronological log of deltas, naturally supporting versioning and time-travel. Some considerations:
- Scenarios where this approach applies: This is generalizable to most use cases discussed in earlier sections.
- Complexity of this approach: This resembles multi-turn dialogue. While later updates may be short, accumulating full history increases context length, which impacts decoding time. Although KV sharing during prefill can reduce computation, its benefit diminishes as context grows.
A potential optimization is edit history compaction—merge old edits into the original context and prune them from the conversation. To retain KV reuse after compaction, KV entries may need to be regenerated asynchronously (i.e., off the critical path).
Replace keywords if identifiable: Recent research shows that Chains-of-Thought can be compressed into key text tokens with little impact on accuracy. This suggests:
If we can identify the key information in context that is likely to change, and correlate it with the generated output, we can perform efficient updates.
The examples below illustrate cases where key information in the input directly influences output, either as a fact or a reasoning bridge (examples from 2WikiMultiHopQA dataset):
-
[Question]: What is the cause of death of the founder of Versus (Versace)?
[Source]: “…Versus (Versace)… a gift by the founder Gianni Versace… Versace was shot and killed…”
[Assistant]: “… shot…” -
[Question]: Who is Dambar Shah’s grandchild?
[Source]: “Doc1:… Dambar Shah … He was the father of Krishna Shah. Doc2: Krishna Shah … He was the father of Rudra Shah.”
[Assistant]: “… Rudra Shah …”
This correlation can help determine whether to skip recomputation or invalidate outputs.
Find sub-paragraphs to recompute: Building on earlier reasoning examples, attention scores might help uncover dependencies between context and output. Consider this example from the glaiveai/RAG-v1 dataset:
The attention heatmap below shows alignment between generated sentences (Y-axis) and context sentences (X-axis). Blue/yellow boxes indicate where output closely follows input content. Columns with low attention were removed (green highlight), and the request was re-run.
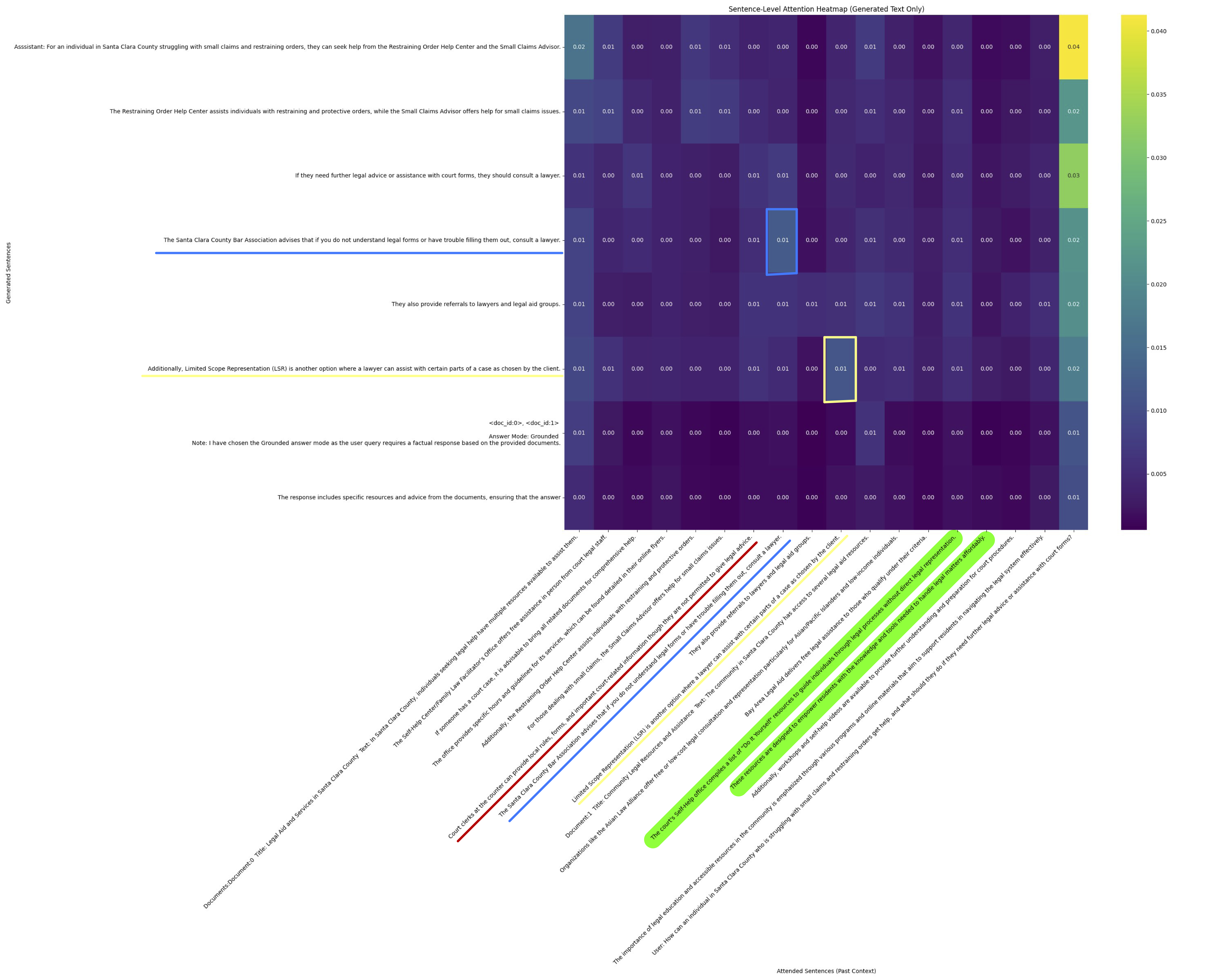
Below, the updated result includes previously seen content (blue/yellow) and also retrieves new context (red box). Overall output remains similar.

In a more complex scenario like multi-hop QA, we can still trace how output depends on intermediate reasoning. Here’s an example from 2WikiMultiHopQA using deepseek-ai/DeepSeek-R1-Distill-Qwen-7B:
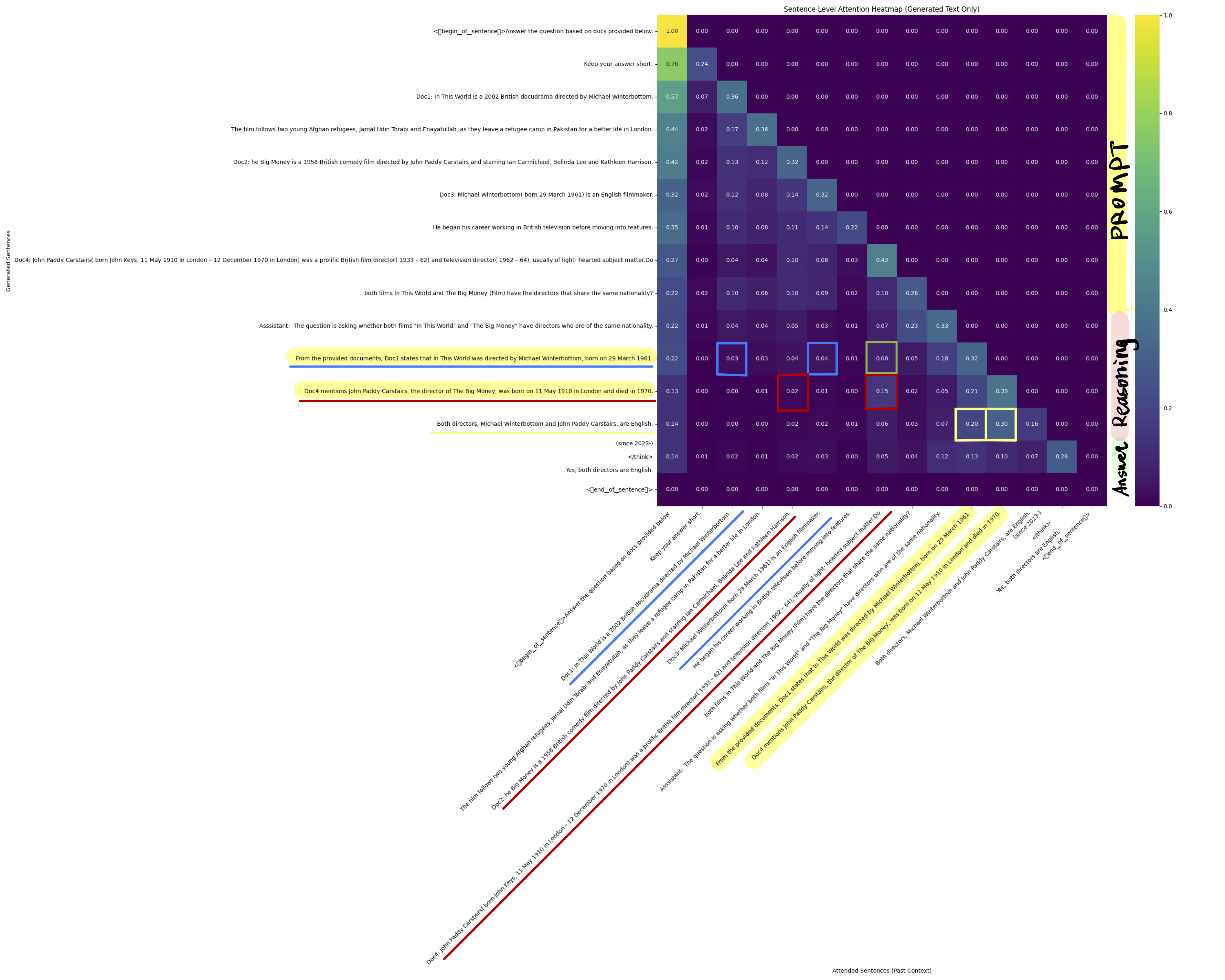
Blue/red boxes highlight direct facts. The yellow box shows the final reasoning step. The model first extracts two key facts before comparison—following the “bridge entity and comparison” pattern in 2WikiMultiHopQA. The blue and red boxes both show higher attention scores compared to other sentences in the prompt (except for the question).
We also know that sentence that contains numbers (e.g., time) typically triggers higher attention score. In this case, the green box has higher attention score than blue boxes in the same row, despite the relevance. This could impact accuracy of dependency detection if attention score is used to track correlation chains.

When I modified birth dates of the directors (irrelevant to the question), attention patterns remained unchanged—as expected.

When I changed a relevant fact—like nationality—the model’s attention shifted only in the reasoning step (yellow/pink boxes), leaving prior attention stable. This suggests fine-grained recomputation is feasible:
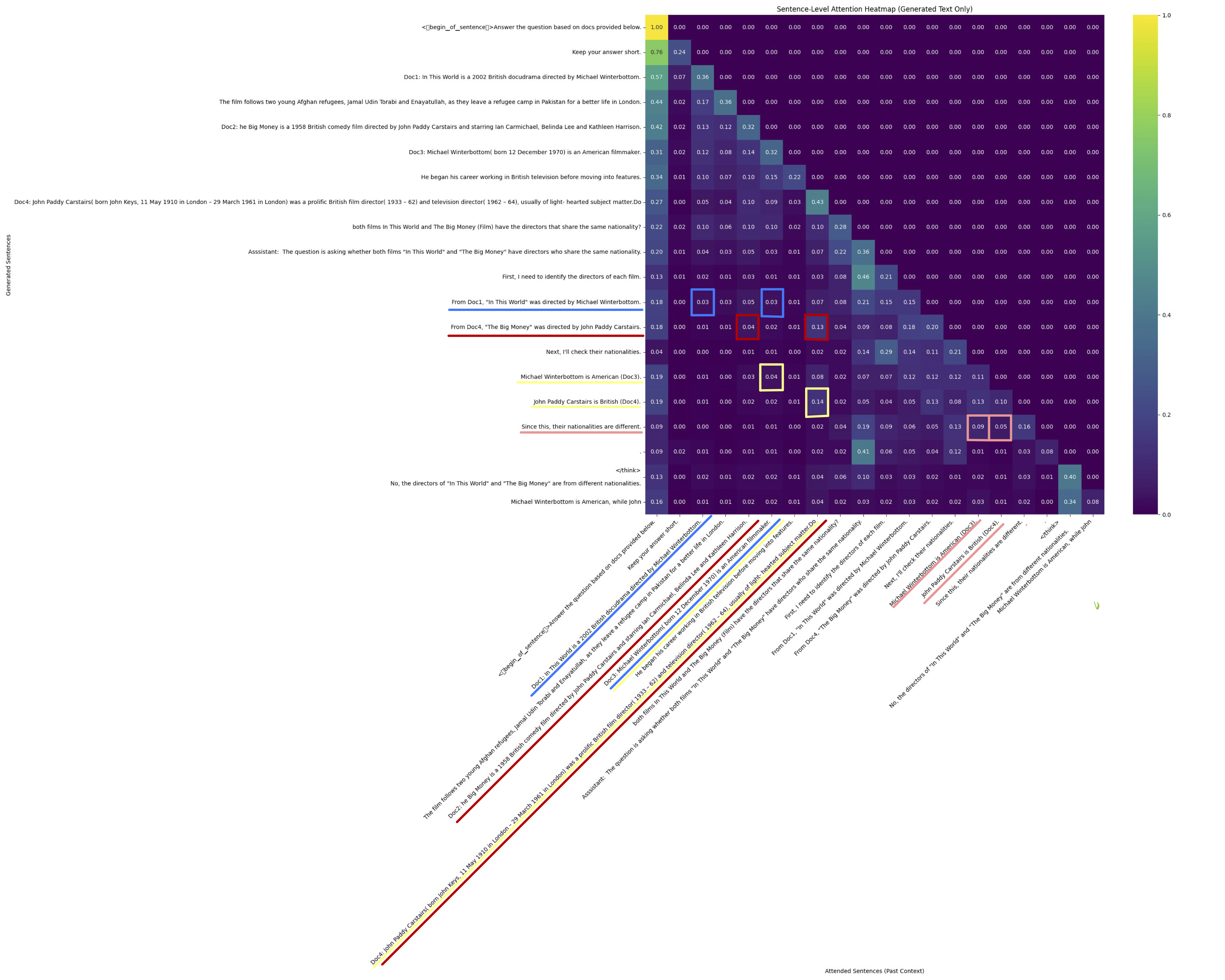
Updates to CONTEXT
Let’s return to our initial continuous view definition:
-- Continuous "query" defining the behavior of an LLM-based chatbot
CREATE CONTINUOUS VIEW response_stream AS
LLM_GENERATE(
PROMPT="Given conversation context and support docs, generate a helpful response.",
CONTEXT=STREAM(conversation_events), -- user interactions, updates incrementally
DATA_SOURCE=STREAM(support_docs_or_events) -- knowledge updates streamed incrementally
);
Earlier, we discussed updates to DATA_SOURCE. What happens when CONTEXT (e.g., user prompt) updates?
The goal remains: reuse past computation whenever possible.
- Reuse intermediate results: Many prompts share overlapping sub-tasks.
Example:- Prompt A: “Are directors of Film A and Film B from the same country?”
- Prompt B: “Who is older: the director of Film A or Film B?”
Both require identifying the directors first.
- Compute incrementally over prior results:
Example:- Prompt: “Plan my TODOs for project X today.”
Might depend on:- A summary of milestones and execution plans (which further depends on summarization of the planning/design documents).
- Tasks assigned during meetings (which further depends on summarization of the conversation in the meeting recordings).
- Prompt: “Plan my TODOs for project X today.”
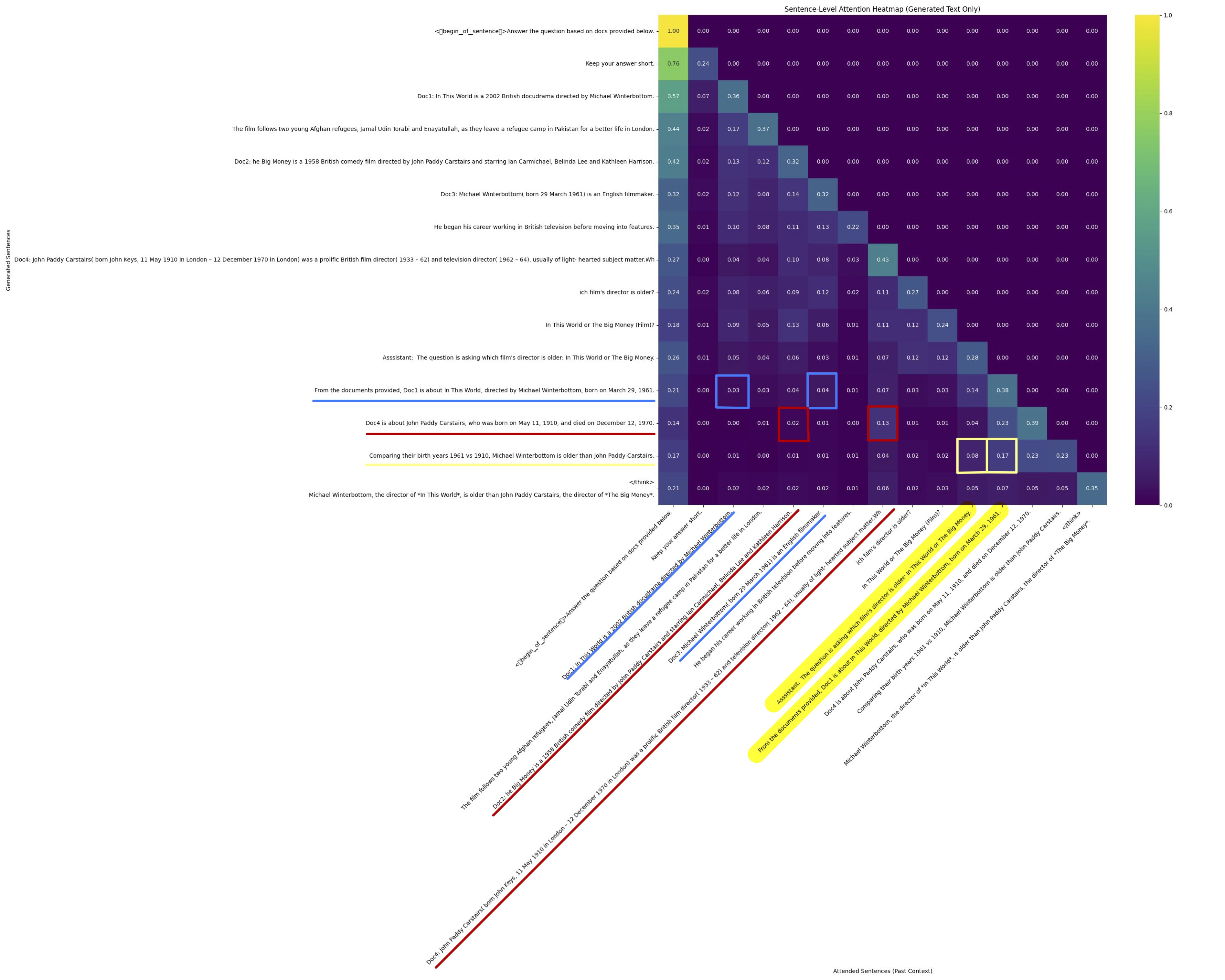
Coming back to the film director example earlier, the first heatmap shows attention score distribution comparing the nationalities of the two directors, as we have seen earlier. I tried changing the question from comparing nationalities of two directors to comparing the ages of the two directors and print out attention score map in the second heatmap.
In this simplistic example, the two attention states, have similar distribution up to the second to last row, which is the generated sentence that reaches the conclusion. Asking different questions does not seem to change the entry with the highest attention scores across different rows, and the first stage of the reasoning steps are similar. Assuming that we are able to identify shared reasoning steps triggered by different questions, the trick is to predict some of the most commonly used partial results based on set of contexts $S(C)$, and find out how these partial results could be reused by comparing the runtime context with all $C$ such that $C \in S(C)$. Possibly related: Test-Time Compute, Parametric RAG, CAG.
I tried changing the question to something unrelated to film director and it is easy to see that the attention map starting from the decoding stage is completely different from the two attention map shown earlier.
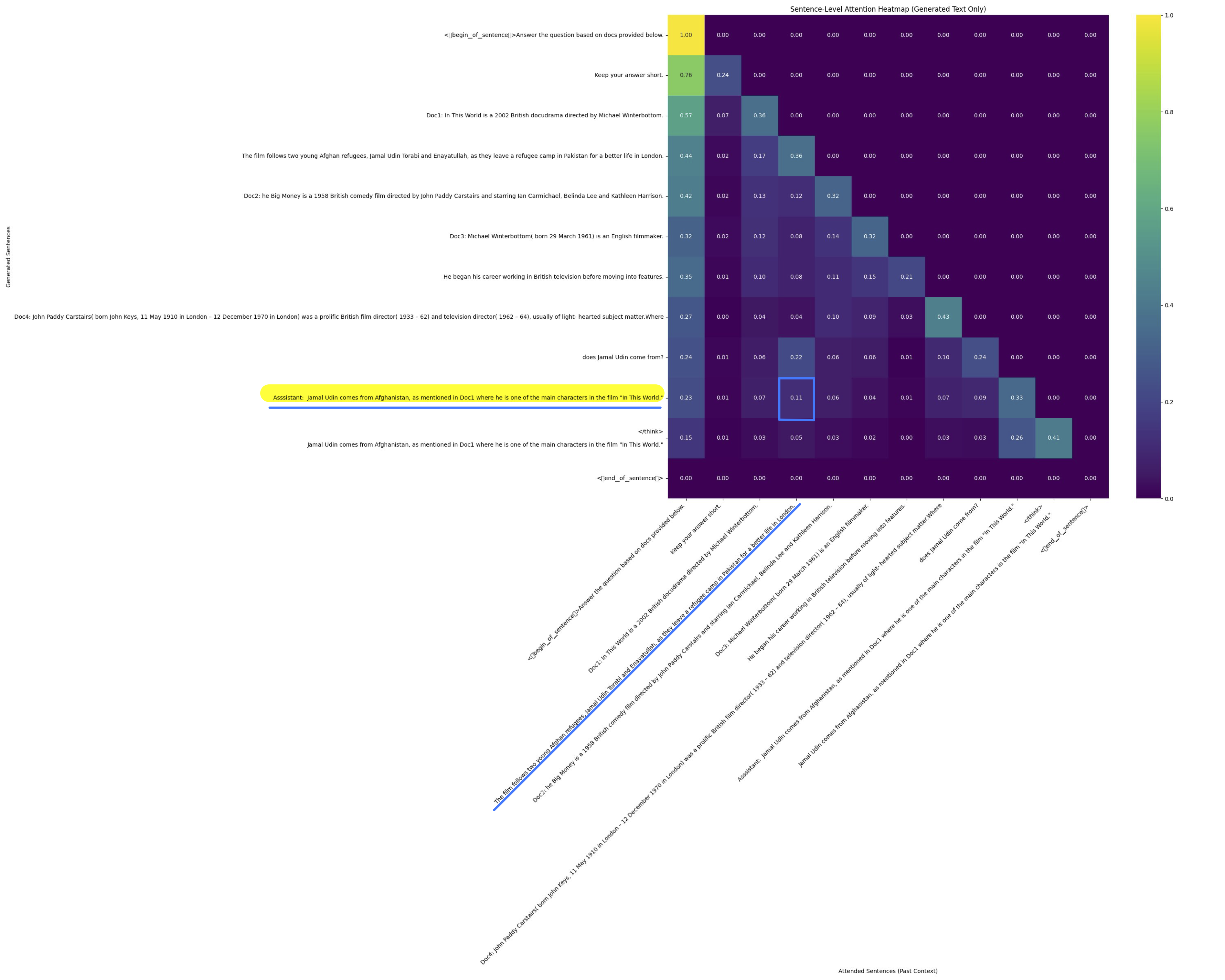
If we are able to make the analogy that updates to the stream of CONTEXT are constantly changing tasks/queries based on fixed pool of source data, and updates to the stream of DATA_SOURCE are constantly updating pool of source data where a single task is based on.
My impression is that updates to CONTEXT is better explored than updates received at DATA_SOURCE based on (probably only a few out of many) papers I had impression on. The obvious question to ask here is that if we treat LLM as a data processing operator (which it is), then this problem would clearly overlap with some of the traditional problems in OLAP systems due to the possibilities of semantic reasoning of new tasks received at the stream of CONTEXT. To make the full analogy, these problems could include the view selection problem, the view maintenance problem, and the query re-writing problem. Specifically, if we use QA as an example, on every question we received at the stream of CONTEXT:
Query Re-writing requires question to be re-written to better match views generated in the past.
View Selection needs a searching mechanism to identify past questions that are semantically similar to the target question (e.g. VectorQ). One question I kept wondering was that whether there is a good way to find a series of “base questions” that we predict will be useful to the questions we receive online – Like the questions like “Which director is older” or “Are these directors are of the same nationality” can be both answered by the combining the answer of “Tell me about the director of film A” and “Tell me about the director of film B”. How to decompose a question into a set of base views that we maintain, and then reason about the performance/cost of using these views are something I’d love to see.
View Maintenance The partial results maintained by set of questions need to be constantly updated as new updates are received at the stream of DATA_SOURCE, which has been discussed earlier.
Thoughts and Questions
Tracking intra-context dependencies?
If we can accurately identify dependency structures, how much can we save?
By default, even small changes to DATA_SOURCE trigger a full prefill (possibly reusable) and a full decode. Ideally, incremental processing avoids recomputation by:
- Saving prefill compute: Predict which KV cache entries are still valid. Many works already exploit sparsity or modular KV reuse.
- Saving decode compute: If outputs remain similar after context changes, we can predict when to reuse vs. regenerate tokens.
This opens doors to innovations like:
- Reusing tokens and KVs
- Exploring KV editing and non-consecutive KV reuse techniques
Semantic-aware KV cache?
Today, KV cache is typically used as a read-append data store and is treated as semantic-agnostic. However, with reasoning models and long-context generation, recent work has been moving toward offloading IO-heavy operations out of HBM—see:
As reasoning becomes more common, we can assume that key information used during decoding will increasingly reside in the KV cache. Exploiting semantic-aware KV cache might enable:
- Token-level KV reuse
- KV editing
- Indexing/versioning in KV cache design
- Layout optimizations for efficient memory transfer
View Maintenance over the Entire Workflow?
So far the discussion on maintaining incremental memory is under the assumption of LLM as a single data processing operator. In practice, the operator could easily be as single step out of a complex multi-step job like workflow/multi-agent scenarios. The multi-step view management could create a problem space for rethinking programming framework along with resource aware optimizations. I haven’t got the time to think deeper into this yet so I’m leaving it here as a space holder for now.
Structured memory vs. implicit reasoning?
Most reasoning models first summarize DATA_SOURCE, then extract reasoning steps. If we can differentiate these steps (i.e., the model’s internal graph), we may better track dependencies between outputs and both source data and intermediate reasoning.
This resembles HippoRAG, where the knowledge graph is explicit. In LLMs, the structure is often implicit—but perhaps can be inferred.
One might ask: why not explicitly convert DATA_SOURCE into a structured form like a knowledge graph?
Pros:
- Incremental maintenance via graph updates
- Explicit dependencies simplify recomputation
Cons:
- Each update may trigger an LLM call
- Updates may invalidate large portions of downstream output
Trade-offs will vary depending on:
- Length of context
- Number of past results being maintained
- Amount of computation that can be skipped
This is similar to the broader debate between long-context LLMs and RAG—more on that in a future discussion.
Emergence of Slow Compute?
The general rationale behind managing semantic-aware memory systems for generative AI is that we should attempt to trade expensive computation for cheaper storage by preserving and reusing processed data. Ideally, LLMs should not need to “re-learn” learned information or only spend marginal cognitive effort to incorporate new knowledge. This allows models to become more capable over time as they:
- Memorize more information,
- Learn the latest updates and store them, and
- Perform inference much faster and more resource-efficiently.
Building incremental memory systems should be part of enabling continual learning for generative AI.
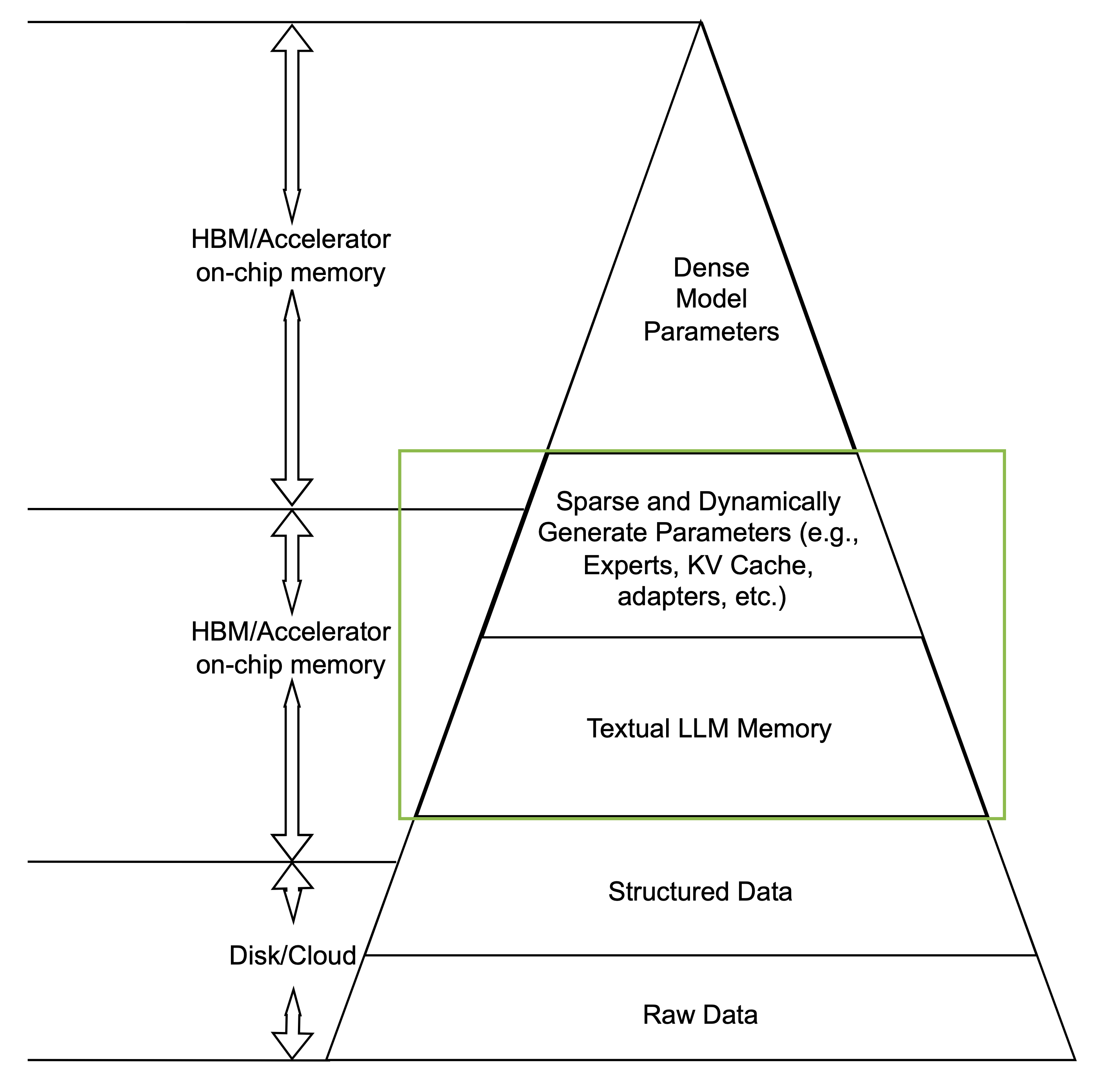
Most of the problems discussed in this post focus on dynamic parameterized memory (e.g., KV cache) and textual memory, shown in the green box above, which should be shared as a service across models and applications. But what does this imply from a system-building perspective?
Incremental processing (if done right) should reduce computation significantly, as discussed previously:
If we choose Append delta as conversation (best generalizability, least cost-effective), the updates are maintained as logs in the textual memory. The challenge then becomes where to maintain update history, as well as how and when to compact the update history to fit within the model’s context window.
If we choose to Recompute sub-paragraphs (medium generalizability, medium cost-effectiveness), we should identify reusable tokens from past results. The generation process would mix decoding and prefilling requests—similar to constraint-decoding. This could fundamentally change engine design, which traditionally assumes LLM inference is a single round of prefill + decode.
Meanwhile, depending on KV cache reusability, this approach could result in frequent, token-level updates to stored KV on every update request, making the KV cache a more compute-intensive component.
In the scenario where Replace keywords (least generalizability, most cost-effective) is possible, the update process could happen directly where results are stored. This eliminates the need for accelerators entirely, enabling “near-storage inference.”
The challenge here is that mappings between key words in source data and inference results must be pre-established offline.
Pre-establishing such mappings, along with other potential directions discussed earlier (e.g., tracking dependency structures, query rewriting, view maintenance and selection), can all be seen as attempts to externalize LLM’s thought process from fast to slow (but larger) storage. Many of these operations are not triggered by immediate requests and must happen off the inference critical path as part of background maintenance.
It is possible, I think, that the focus of building LLM serving stacks will start shifting—from purely optimizing inference tasks on fast compute devices (e.g., accelerators)—to more collaborative, full-stack solutions that leverage slow compute (i.e., near-storage) to enhance real-time inference, both in terms of performance and efficiency. This shift is likely to emphasize areas such as memory optimization techniques, efficient dependency tracking mechanisms, hybrid compute architectures that balance fast and slow compute, and innovative caching strategies to maximize reuse of intermediate results.
]]>